Analysts See Possible Final Flush
Analysts See Possible Final Flush  Immutable Partners Kadath Studio to Launch Free-to-Play Trading Card Game Call of Myth
Immutable Partners Kadath Studio to Launch Free-to-Play Trading Card Game Call of Myth  Aave rolls out V4 testnet with developer preview of upcoming “Pro” experience
Aave rolls out V4 testnet with developer preview of upcoming “Pro” experience  Dogecoin Price Forecast: DOGE could retest $0.14
Dogecoin Price Forecast: DOGE could retest $0.14  Crypto market update #bitcoin
Crypto market update #bitcoin 
















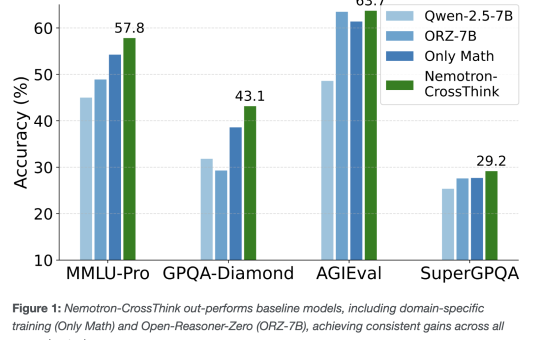
Scaling Reinforcement Learning Beyond Math: Researchers from NVIDIA AI and CMU Propose Nemotron-CrossThink for Multi-Domain Reasoning with Verifiable Reward Modeling
Large Language Models (LLMs) have demonstrated remarkable reasoning capabilities across diverse tasks, with Reinforcement Learning (RL) serving as a crucial...