Analysts See Possible Final Flush
Analysts See Possible Final Flush  Immutable Partners Kadath Studio to Launch Free-to-Play Trading Card Game Call of Myth
Immutable Partners Kadath Studio to Launch Free-to-Play Trading Card Game Call of Myth  Aave rolls out V4 testnet with developer preview of upcoming “Pro” experience
Aave rolls out V4 testnet with developer preview of upcoming “Pro” experience  Dogecoin Price Forecast: DOGE could retest $0.14
Dogecoin Price Forecast: DOGE could retest $0.14  Crypto market update #bitcoin
Crypto market update #bitcoin 
















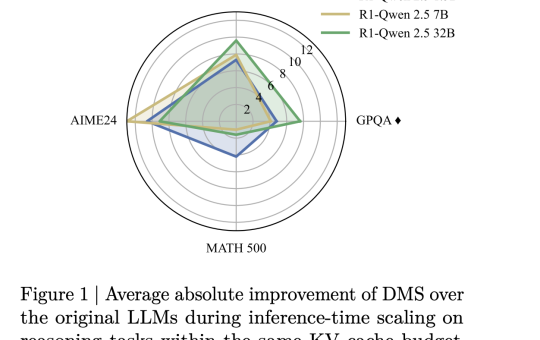
NVIDIA Researchers Introduce Dynamic Memory Sparsification (DMS) for 8× KV Cache Compression in Transformer LLMs
As the demand for reasoning-heavy tasks grows, large language models (LLMs) are increasingly expected to generate longer sequences or parallel...